I am just testing how far the built in blogger editor can help in laying out proofs. Please ignore this.
Question: prove distributivity of OR over OR ( I am using "OR" and "AND" for disjunction and conjunction operators , == for equivalence. The reasoning for each step is to the side after a --),
(The calculus used is EQ from "A logical Approach to Discrete Math". This is theorem 3.41, just something chosen at random - but I've used only axioms + theorems proven till that point in the book ) .
prove p OR (q OR r) == (p OR q) OR (p OR r)
p OR (q OR r) -- LHS
== ((p OR q) OR r) -- associativity of Or
== (( p OR q) OR r) OR false -- False is the identity of OR
== (( p OR q) OR r) OR (NOT true) -- definition of false
== (m or r) OR (NOT true) -- substituting m for (p OR q), Leibniz
== m OR (r OR (NOT true)) -- associativity of OR
== m OR ( r OR (NOT (p == p)) ) -- true is identity of ==
== m OR ( r OR ( NOT p == p )) -- distributivity of NOT over ==
== m OR (r OR (NOT p) == r OR p ) -- distributivity of OR over ==
== m OR (r OR p == r OR (NOT p)) -- symmetry of OR
== (m OR r OR p) == (m OR r OR (NOT p)) -- distributivity of OR over ==
==(p OR q OR r OR p)== (m OR r OR (NOT p)) -- replacing m with (p OR q), Leibniz
==(p OR q) OR (r OR p)== (m OR r OR (NOT p)) --associativity of OR
==(p OR q) OR (p OR r)== (m OR r OR (NOT p)) --symmetry of OR
==(p OR q) OR (p OR r)== (m OR (NOT p) OR r) --symmetry of OR
==(p OR q) OR (p OR r)== (p OR q OR (NOT p) OR r) --expanding m to p OR q, Leibniz
==(p OR q) OR (p OR r)== (p OR (NOT p) OR q OR r) --symmetry of OR
==(p OR q) OR (p OR r)== ( true OR q OR r) -- Excluded Middle
== (p OR q) OR (p OR r)== ( true OR r) -- true is the Zero of OR
== (p OR q) OR (p OR r) == true -- true is the Zero of OR
== (p OR q) OR (p OR r) -- true is the Identity of ==
== RHS . QED
Conclusion: What a mess. I need Latex dammit. Anyone know of a *non* wordpress blog with a latex plugin? (I don't want JS rendering, for which there are a few options. I want an image (png, gif, jpeg whatever) generated on the server and plugged in appropriately).
Monday, February 15, 2010
Monday, May 18, 2009
Some guidelines on porting
This is in response to some difficulties encountered by a friend in porting a library from Common Lisp to Scheme. I am very short of time so this is less polished than usual. Apologies in advance.
I generally port something from one language to another when
(1) I want to learn a new language. I learned Ruby by porting the FIT library from Java. It ended up in my never using FIT and not seeing enough of a reason to shift my choice of scripting language from Python, but it was still an interesting exerscise.
(2) My clients need to work with or on the *code* I deliver. If a scientist has to look at or modify code, for example then the final deliverable has to be in a mainstream language like Python or Java vs a more powerful language like Erlang or Haskell or even Scheme.(though I can sometimes get away with Scheme). So I prototype in whatever language seems appropriate to the domain and then port it to Java or Python or C.
After doing this a few times, I've found a few "shortcuts".
(1) There are three variables - the source language, the target language, the domain. Make sure you know at *least* two of them at the expert level. If you don't, fix that first. Struggling with two things at the same time(say the domain and the target language) is a recipe for suboptimal outcomes.
(2) Do NOT port line by line from source to target. Even when the source and target languages are roughly similair, say Python to Ruby, or Scheme to Common Lisp, doing this often misses the idioms of the target language and ends up looking stilted. Eg. "meta programming" in Ruby (vs Python) and iteration in Scheme (vs Common Lisp).
(3) DO use an intermediate form. This is, in my experience, *the* key to a succesful port. The intermediate form could be English, ("here the foo is converted to baz via a fold left accumulator combo") Logic, pseudo code, whatever is appropriate. Translate from the source code to the intermediate language (at multiple levels - function, module, design and architecture) and then from the intermediate language to the target language. In the latter step write *idiomatic* target language. Beware the idioms of the source language leaking into the target language.
(4) When the source and target languages have different paradigms (say Prolog (logic)to Java ( a kind of bastardised OO) ) make sure you are fluent in both *paradigms* before you undertake the translation. Otherwise, you often end up with ugly code. A variant of this occurs when you are moving up or down the "blub ladder", even within the same paradigm say smalltalk to Java or C to Pascal.
Moving down is tedious but often conceptually straightforward. Moving up is harder in a different way because the lesser language often hides abstractions that are directly expressible in the higher (a complicated nest of for next lops. ifs and assignments may (in the end) decompose cleanly into sequence ops in haskell but it is sometimes difficult to see and/or extract those).
I generally port something from one language to another when
(1) I want to learn a new language. I learned Ruby by porting the FIT library from Java. It ended up in my never using FIT and not seeing enough of a reason to shift my choice of scripting language from Python, but it was still an interesting exerscise.
(2) My clients need to work with or on the *code* I deliver. If a scientist has to look at or modify code, for example then the final deliverable has to be in a mainstream language like Python or Java vs a more powerful language like Erlang or Haskell or even Scheme.(though I can sometimes get away with Scheme). So I prototype in whatever language seems appropriate to the domain and then port it to Java or Python or C.
After doing this a few times, I've found a few "shortcuts".
(1) There are three variables - the source language, the target language, the domain. Make sure you know at *least* two of them at the expert level. If you don't, fix that first. Struggling with two things at the same time(say the domain and the target language) is a recipe for suboptimal outcomes.
(2) Do NOT port line by line from source to target. Even when the source and target languages are roughly similair, say Python to Ruby, or Scheme to Common Lisp, doing this often misses the idioms of the target language and ends up looking stilted. Eg. "meta programming" in Ruby (vs Python) and iteration in Scheme (vs Common Lisp).
(3) DO use an intermediate form. This is, in my experience, *the* key to a succesful port. The intermediate form could be English, ("here the foo is converted to baz via a fold left accumulator combo") Logic, pseudo code, whatever is appropriate. Translate from the source code to the intermediate language (at multiple levels - function, module, design and architecture) and then from the intermediate language to the target language. In the latter step write *idiomatic* target language. Beware the idioms of the source language leaking into the target language.
(4) When the source and target languages have different paradigms (say Prolog (logic)to Java ( a kind of bastardised OO) ) make sure you are fluent in both *paradigms* before you undertake the translation. Otherwise, you often end up with ugly code. A variant of this occurs when you are moving up or down the "blub ladder", even within the same paradigm say smalltalk to Java or C to Pascal.
Moving down is tedious but often conceptually straightforward. Moving up is harder in a different way because the lesser language often hides abstractions that are directly expressible in the higher (a complicated nest of for next lops. ifs and assignments may (in the end) decompose cleanly into sequence ops in haskell but it is sometimes difficult to see and/or extract those).
Friday, May 8, 2009
Twittering
here.
I am not completely convinced of the awesomeness of Twitter, but it seems useful to jot down thoughtlets not big enough for a complete blog entry.
We'll see how it goes.
I am not completely convinced of the awesomeness of Twitter, but it seems useful to jot down thoughtlets not big enough for a complete blog entry.
We'll see how it goes.
Tuesday, March 24, 2009
Ada Lovelace Day: Daphne Koller
Via Sunayana's Blog I came to know about the Ada Lovelace Day pledge whereby people write about women in computing they admire.
Now, I am personally not convinced there is a real crisis surrounding a "lack of women in computing". My attitude towards "women in computing" is expressed perfectly in George RR Martin's Novel "A Game of Thrones" by Syrio Forel, The First Sword of Bravos, when he is teaching Arya Stark, who is a very atypical girl, - given the medival setting of the story - and a bit of a tomboy, the finer points of sword fighting. He calls her "boy" a few too many times till she gets irritated and says "But I am a girl" And Syrio replies , "Boy, Girl you are a sword". Likewise for me, in computing , "Boy, Girl, you are a mind" I could care less about a person's chromosomal makeup.
That said , let me talk about a mind I admire, which happens to reside in a woman' body. :-)
Daphne Koller is a professor at Stanford whose research is about applying probabilistic techniques to complex domains. I've never met her (I should be lucky enough to study in Stanford!) but I've exchanged a few emails with her.
I was coding up a robotics algorithm and the paper elucidating the algorithm had a reference to one of her papers, "Using learning for approximation in stochastic processes". This paper explained a brilliant, elegant idea - in essence, instead of, in a particle filter (say) generating the t+ 1'th generation of particles from the t'th generation, the idea is to (a) create a probability distribution pd from the t'th generation and (b) sample from pd to get the t+1th generation.
Unfortunately there wasn't enough information in the paper to code up a density tree , so I wrote to Dr Koller asking her if she had some code available. She didn't, (the code was lost a long time ago!) but she very graciously supplied me with enough detail so I could figure out the data structure myself and successfully complete my coding effort.
Dr Koller's papers are a treasure trove for anyone interested in her research areas and she is tremendously admired within the research community.Very few people combine brilliance and grace. Dr Koller is one of them. She is a great role model for anyone in computing (irrespective of chromosmal make up) to look up to and learn from
Now, I am personally not convinced there is a real crisis surrounding a "lack of women in computing". My attitude towards "women in computing" is expressed perfectly in George RR Martin's Novel "A Game of Thrones" by Syrio Forel, The First Sword of Bravos, when he is teaching Arya Stark, who is a very atypical girl, - given the medival setting of the story - and a bit of a tomboy, the finer points of sword fighting. He calls her "boy" a few too many times till she gets irritated and says "But I am a girl" And Syrio replies , "Boy, Girl you are a sword". Likewise for me, in computing , "Boy, Girl, you are a mind" I could care less about a person's chromosomal makeup.
That said , let me talk about a mind I admire, which happens to reside in a woman' body. :-)
Daphne Koller is a professor at Stanford whose research is about applying probabilistic techniques to complex domains. I've never met her (I should be lucky enough to study in Stanford!) but I've exchanged a few emails with her.
I was coding up a robotics algorithm and the paper elucidating the algorithm had a reference to one of her papers, "Using learning for approximation in stochastic processes". This paper explained a brilliant, elegant idea - in essence, instead of, in a particle filter (say) generating the t+ 1'th generation of particles from the t'th generation, the idea is to (a) create a probability distribution pd from the t'th generation and (b) sample from pd to get the t+1th generation.
Unfortunately there wasn't enough information in the paper to code up a density tree , so I wrote to Dr Koller asking her if she had some code available. She didn't, (the code was lost a long time ago!) but she very graciously supplied me with enough detail so I could figure out the data structure myself and successfully complete my coding effort.
Dr Koller's papers are a treasure trove for anyone interested in her research areas and she is tremendously admired within the research community.Very few people combine brilliance and grace. Dr Koller is one of them. She is a great role model for anyone in computing (irrespective of chromosmal make up) to look up to and learn from
Sunday, March 22, 2009
GnuPlot In Action
is a great (e)book. I got the early access version from Manning and it is very well written. Phillip Jaanert has done a great job. I've been using it to visualize the output of some algorithms I've been coding up.
here is a graph I created with GnuPlot for the optimal decisions for different learning rates for 2000 one armed bandits (essentially a stateless value function less precursor to Reinforcement Learning)
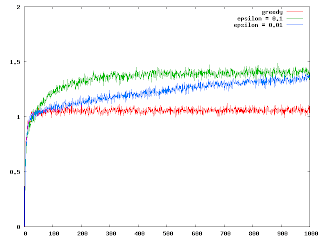
here is a graph I created with GnuPlot for the optimal decisions for different learning rates for 2000 one armed bandits (essentially a stateless value function less precursor to Reinforcement Learning)

Saturday, February 21, 2009
Gitting It after all
I finally moved to git (from Subversion). The key to understanding git is to understand how the various "objects" (blobs, trees, commits and tags) form a Directed Acyclic Graph, and then understand the various version control commands in terms of modifications of and traversals on this data structure. Approaching GIT from a "this is another version control system like [your favorite VCS]" is the *wrong* way to go and results in people end up confused because then git will seem to be doing things (annoyingly) differently from what they are used to.
The one minor nitpick I have is that most of the java ide s don't work well with git, but at least to me that is a blessing in disguise. I had planned to do a project with the Java/Eclipse combination but git (and the development workflow it enables) was so compelling that I am using Emacs and Haskell instead.
Which is a definite win. :-)
Update:- Apparently the Intellij IDE has a GIT plugin in the latest version. I greatly admire the product, though I don't use it myself these days.
The one minor nitpick I have is that most of the java ide s don't work well with git, but at least to me that is a blessing in disguise. I had planned to do a project with the Java/Eclipse combination but git (and the development workflow it enables) was so compelling that I am using Emacs and Haskell instead.
Which is a definite win. :-)
Update:- Apparently the Intellij IDE has a GIT plugin in the latest version. I greatly admire the product, though I don't use it myself these days.
Friday, February 6, 2009
Exploring Game Engines
A few of us meet on the last Saturday of every month to review our technical progress (or the lack of it). This is somewhat like an iteration meeting in an agile project but focussed on personal achievement. I've written on such "Loser's Club" meetings before.
Recently we added a new wrinkle - each participant of the monthly meeting sends a weekly progress report to the others explaining what he worked on this week.
The following is the (lightly edited) report I sent a few minutes ago.
For the first time in a very long time I worked every day of the week without unnecessary distractions.
As you know, I am working on an AI simulation project. Visualization is a key component and to understand how best to do this, I've been working on understanding the game loop in game engines and what modifications need to be made to use it in simulations. There seems to be a trade off between running the simulation as fast as the hardware allows (needed for effective sims) and slowing the simulation down to (some small multiple of) the screen refresh rate (typically 50-75 Hz) so humans can interact effectively. Networking multiple machines (the simulations needs to, ultimately, run on a cluster) has design implications on implementing the Game Clock (or Sim Clock).
One approach is to completely decouple the sim (which could write the results out into a file, say) and the display (which could work off that file). For some algorithms, ( eg Apprenticeship Learning) , where human intervention and process modeling is part of the learning process, this approach would be problematic, and anyway networking is still an issue, so I need to find a good approach).
I have the beginnings of a really nice game framework (if I do say so myself). I have implemented multiple buffering strategies (pointer flips vs image redraw - The j2se comes with all this bundled up but since the final implementation will not be in Java I am implementing them from scratch to get a good understanding of how it works - only machine for e.g pointer flips give a 50 % boost to the fps), image loading, and a controller that allows either human or algorithm control (most game engines tie the event handling into the guts of the game).
I've attached a (really yucky for now) screenshot. It just shows some sprites moving against a nondescript background, but I am doing some interesting experiments behind the scenes.
In the coming week, I hope to resolve the sim vs game timing issue and also understand (a) tiled backgrounds and (b) how level editors work.
Regards,
The act of writing out what was accomplished every week is very helpful. There's nothing like having to write "Nothing useful accomplished this week" a few times in a row, to alert one to the fact that your life is flowing down the drain!
Last week, I also read "One Jump Ahead:: Challenging Human Supremacy In Checkers", which is an account by Dr.Jonathan Schaeffer of how he built Chinook, a program to beat the Checkers World Champion. This is a very interesting and (to researchers) very inspiring book. Jonathan also explains how he went on to solve Checkers (in the sense that Tic Tac Toe is a completely solved game). All in all, a great account of how research is really done.
Recently we added a new wrinkle - each participant of the monthly meeting sends a weekly progress report to the others explaining what he worked on this week.
The following is the (lightly edited) report I sent a few minutes ago.
For the first time in a very long time I worked every day of the week without unnecessary distractions.
As you know, I am working on an AI simulation project. Visualization is a key component and to understand how best to do this, I've been working on understanding the game loop in game engines and what modifications need to be made to use it in simulations. There seems to be a trade off between running the simulation as fast as the hardware allows (needed for effective sims) and slowing the simulation down to (some small multiple of) the screen refresh rate (typically 50-75 Hz) so humans can interact effectively. Networking multiple machines (the simulations needs to, ultimately, run on a cluster) has design implications on implementing the Game Clock (or Sim Clock).
One approach is to completely decouple the sim (which could write the results out into a file, say) and the display (which could work off that file). For some algorithms, ( eg Apprenticeship Learning) , where human intervention and process modeling is part of the learning process, this approach would be problematic, and anyway networking is still an issue, so I need to find a good approach).
I have the beginnings of a really nice game framework (if I do say so myself). I have implemented multiple buffering strategies (pointer flips vs image redraw - The j2se comes with all this bundled up but since the final implementation will not be in Java I am implementing them from scratch to get a good understanding of how it works - only machine for e.g pointer flips give a 50 % boost to the fps), image loading, and a controller that allows either human or algorithm control (most game engines tie the event handling into the guts of the game).

I've attached a (really yucky for now) screenshot. It just shows some sprites moving against a nondescript background, but I am doing some interesting experiments behind the scenes.
In the coming week, I hope to resolve the sim vs game timing issue and also understand (a) tiled backgrounds and (b) how level editors work.
Regards,
The act of writing out what was accomplished every week is very helpful. There's nothing like having to write "Nothing useful accomplished this week" a few times in a row, to alert one to the fact that your life is flowing down the drain!
Last week, I also read "One Jump Ahead:: Challenging Human Supremacy In Checkers", which is an account by Dr.Jonathan Schaeffer of how he built Chinook, a program to beat the Checkers World Champion. This is a very interesting and (to researchers) very inspiring book. Jonathan also explains how he went on to solve Checkers (in the sense that Tic Tac Toe is a completely solved game). All in all, a great account of how research is really done.
Friday, January 30, 2009
Fad Alert
With a subsection of the Ruby Fanboy crowd moving to Clojure, there is a lot of uninformed talk about Software Transactional Memory (STM), mostly regarding how it "solves" concurrency in a multiple core scenario and how it is very "intuitive".
Bryan Cantrill restores sanity to the discussion via his blog post, "Concurrency's Shysters"(Be sure to read the ACM paper he refers to in the post).
Unless you really understand the various concurrency mechanisms, to the point where you can implement some of them and know the theory therof, please please don't code concurrent programs. Thanks in advance.
PS: This is not a knock on Clojure itself. Rich Hickey, its creator, is extremely talented, dedicated and very knowledgeable. Clojure is a great piece of software. This post is a reaction to some uninformed enterprise developers' mumblings on how Clojure is the next bandwagon to jump on.
Bryan Cantrill restores sanity to the discussion via his blog post, "Concurrency's Shysters"(Be sure to read the ACM paper he refers to in the post).
Unless you really understand the various concurrency mechanisms, to the point where you can implement some of them and know the theory therof, please please don't code concurrent programs. Thanks in advance.
PS: This is not a knock on Clojure itself. Rich Hickey, its creator, is extremely talented, dedicated and very knowledgeable. Clojure is a great piece of software. This post is a reaction to some uninformed enterprise developers' mumblings on how Clojure is the next bandwagon to jump on.
Monday, January 19, 2009
Book Treks
Working through every single exercise in a good technical book is a fascinating (and educational!) endeavour. Two of my friends are working through some tough technical books in this fashion (and blogging about it).
My friend Manoj wanted to take a break from writing J2EE code and so took a sabbatical to work through SICP. He is blogging his progress here. Another friend, Himanshu, is working through Van Roy and Haridi's "Concepts, Techniques and Models of Computer Programming" and is putting up the answers to the exercises here.
My friend Manoj wanted to take a break from writing J2EE code and so took a sabbatical to work through SICP. He is blogging his progress here. Another friend, Himanshu, is working through Van Roy and Haridi's "Concepts, Techniques and Models of Computer Programming" and is putting up the answers to the exercises here.
Thursday, December 25, 2008
Two levels of mathematics
I've written about the connection between programming and mathematics before. My latest discovery is that there are two "levels" (for lack of a better word) Mathematics - one inhabited by engineers and one by mathematicians. This divide seems to carry over into books as well - thus, taking Calculus as an example, Gilbert Strang's book is an Engineer's guide and Spivak's book is for mathematicians.I am working through the latter, and while it is very clearly written, it is a whole different level from any book on Calculus I've worked with before.
Friday, October 3, 2008
An Unsatisfactory Proof
To be proved
"If the symmetric difference of sets A and B is a subset of A, prove that B is a subset of A"
symmetric difference of A and B = A U B \ A ^ B (using U for union , ^ for intersection and \ for difference).
What I've come up with
The Proof
Let x be an arbitrary element of B.
Then x is also an element of A (case 1) or it is not (case 2).
case 1.
If an arbitrary element of B is an element of A then B is a subset of A .
case 2.
x is an element of B but is not an element of A. In which case, it is an element of (A U B) \ ( A ^ B), ie it is an element of the symmetric difference of the sets A and B. Since it is given that the symmetric difference of A and B is a subset of A, x is an element of A.
Since x is an element of A in both cases and since x is an arbitrary element of B, we conclude that B is a subset of A.
Q.E.D
I keep getting the feeling there is a more elegant way to prove this. If anyone wants to write to me (or comment here) I'd appreciate it much.
PS: - the proposition is obviously true (draw a Venn diagram to see why). I am asking for help on the (structure of the) proof itself.
"If the symmetric difference of sets A and B is a subset of A, prove that B is a subset of A"
symmetric difference of A and B = A U B \ A ^ B (using U for union , ^ for intersection and \ for difference).
What I've come up with
The Proof
Let x be an arbitrary element of B.
Then x is also an element of A (case 1) or it is not (case 2).
case 1.
If an arbitrary element of B is an element of A then B is a subset of A .
case 2.
x is an element of B but is not an element of A. In which case, it is an element of (A U B) \ ( A ^ B), ie it is an element of the symmetric difference of the sets A and B. Since it is given that the symmetric difference of A and B is a subset of A, x is an element of A.
Since x is an element of A in both cases and since x is an arbitrary element of B, we conclude that B is a subset of A.
Q.E.D
I keep getting the feeling there is a more elegant way to prove this. If anyone wants to write to me (or comment here) I'd appreciate it much.
PS: - the proposition is obviously true (draw a Venn diagram to see why). I am asking for help on the (structure of the) proof itself.
Friday, September 5, 2008
The key to understanding proofs
is to realize that the exposition of a proof is distinct from its derivation. The (published) exposition is a very condensed description of the what and why. The (usually unpublished) derivation is about the how (the proof was derived). Reading carefully between the lines of the exposition one can often discern a faint outline of the creator's thought process but that's about it.
A (weak) analogy is having the binary code of a program that does something wonderful.Without the source code(the step by step derivation of the proof), one has to use disassemblers (digging into the exposition)to figure out how it works. Having the source code would be better in some contexts, but most proofs are "binary only".
Having said that, nothing stops me from starting from the givens and trying to prove the conclusion myself, which is a worthwhile exercise in itself. ("worthwhile" as in "what does not kill me makes me stronger" ;-) )
A (weak) analogy is having the binary code of a program that does something wonderful.Without the source code(the step by step derivation of the proof), one has to use disassemblers (digging into the exposition)to figure out how it works. Having the source code would be better in some contexts, but most proofs are "binary only".
Having said that, nothing stops me from starting from the givens and trying to prove the conclusion myself, which is a worthwhile exercise in itself. ("worthwhile" as in "what does not kill me makes me stronger" ;-) )
Saturday, July 12, 2008
The JVM and Tail Recursion
In an attempt to investigate the performance of a trampolined interpreter on the JVM, I discovered something interesting.
First, some background. In essence, trampolining is a strategy used to avoid stack overflow on platforms (like the JVM) that save to the stack even when not necessary , e,g while doing a tail recursive function call. So after doing a CPS transform and then trampolining it by returning a lambda wrapped "thunk", my interpreter *should have* handled an infinite tail recursive call *without* a stack overflow exception. But it failed anyway!
After Dan Friedman pointed out (by email) that "If you use exceptions in Java, you will regain tail recursion. I think that is the only way to get around Java. ", I did some digging and found something even more interesting.
Tail recursive (java) functions are properly handled by some java JVMs (specifically the JITs) and not others! See this article for a good explanation.
Try running Listings 4 and 5 (from the referenced article) on your JVM :-D . I suspect that C# code equivalent to the two listings in the article (numbered 4 and 5) would both run perfectly. Can someone with a Windows machine and dotNet installed let me know if it works? (post a comment here or send me email! Thanks in advance!)
Footnote: the conversion of the tail recursive function (in the article) into the while loop form is one example of how a trampolining interpreter could "break stack build up".
First, some background. In essence, trampolining is a strategy used to avoid stack overflow on platforms (like the JVM) that save to the stack even when not necessary , e,g while doing a tail recursive function call. So after doing a CPS transform and then trampolining it by returning a lambda wrapped "thunk", my interpreter *should have* handled an infinite tail recursive call *without* a stack overflow exception. But it failed anyway!
After Dan Friedman pointed out (by email) that "If you use exceptions in Java, you will regain tail recursion. I think that is the only way to get around Java. ", I did some digging and found something even more interesting.
Tail recursive (java) functions are properly handled by some java JVMs (specifically the JITs) and not others! See this article for a good explanation.
Try running Listings 4 and 5 (from the referenced article) on your JVM :-D . I suspect that C# code equivalent to the two listings in the article (numbered 4 and 5) would both run perfectly. Can someone with a Windows machine and dotNet installed let me know if it works? (post a comment here or send me email! Thanks in advance!)
Footnote: the conversion of the tail recursive function (in the article) into the while loop form is one example of how a trampolining interpreter could "break stack build up".
Wednesday, July 2, 2008
Directions
This is the first post on my brand new blog. The essential difference between this blog and the old one is a change of "voice" and focus.
Unlike the "catch all" nature of the old blog, this one will have a sharper focus, specifically on things technical (mostly code/mathematics/algorithms etc - but "technical" is used very broadly - I could very well end up dissecting the Black Scholes Equation for pricing derivatives, for example.). I will create a separate blog for non technical ruminations (TBD).
So what's happening on my end? Life is insanely busy (as usual) and I am meeting great people (as usual) and situations (as usual) and the great difficulty (as always) is choosing among the zillion challenges to tackle next. "So little done, so much to do", to quote Cecil Rhodes, but hey it beats a boring, "normal" life any day.
On the technical/programming front, I am investigating the impact of various (language) interpreter designs on execution time. Over the coming weekend, for example, I am trying to get some sense of how much overhead trampolining adds to interpretation time (vs a normal recursive descent parser).
So that is what I'll write about in the next few entries. And then there is the reinforcement learning library I wrote for the good folks in the DRDO (Defence Research Development Organization for non Indian readers). I could probably spin that off into an open source project once I (find some time to) tidy it up a bit.
Then there's the derivation of concurrent algorithms, the relational-algebra to SQL query generator thingy I've been fiddling with off and on for a while now, and thoughts on programming with typed channels and machine learnng algorithms as programming primitives. Lots of interesting things to write about.
Stay tuned.
Hello Word! It is good to be back.
Unlike the "catch all" nature of the old blog, this one will have a sharper focus, specifically on things technical (mostly code/mathematics/algorithms etc - but "technical" is used very broadly - I could very well end up dissecting the Black Scholes Equation for pricing derivatives, for example.). I will create a separate blog for non technical ruminations (TBD).
So what's happening on my end? Life is insanely busy (as usual) and I am meeting great people (as usual) and situations (as usual) and the great difficulty (as always) is choosing among the zillion challenges to tackle next. "So little done, so much to do", to quote Cecil Rhodes, but hey it beats a boring, "normal" life any day.
On the technical/programming front, I am investigating the impact of various (language) interpreter designs on execution time. Over the coming weekend, for example, I am trying to get some sense of how much overhead trampolining adds to interpretation time (vs a normal recursive descent parser).
So that is what I'll write about in the next few entries. And then there is the reinforcement learning library I wrote for the good folks in the DRDO (Defence Research Development Organization for non Indian readers). I could probably spin that off into an open source project once I (find some time to) tidy it up a bit.
Then there's the derivation of concurrent algorithms, the relational-algebra to SQL query generator thingy I've been fiddling with off and on for a while now, and thoughts on programming with typed channels and machine learnng algorithms as programming primitives. Lots of interesting things to write about.
Stay tuned.
Hello Word! It is good to be back.
Subscribe to:
Posts (Atom)